7.6 字符串、数组和切片的应用
7.6.1 从字符串生成字节切片
假设 s 是一个字符串(本质上是一个字节数组),那么就可以直接通过 c := []bytes(s) 来获取一个字节的切片 c。另外,您还可以通过 copy 函数来达到相同的目的:copy(dst []byte, src string)。
同样的,还可以使用 for-range 来获得每个元素(Listing 7.13—for_string.go):
package main
import "fmt"
func main() {
s := "\u00ff\u754c"
for i, c := range s {
fmt.Printf("%d:%c ", i, c)
}
}
输出:
0:ÿ 2:界
我们知道,Unicode 字符会占用 2 个字节,有些甚至需要 3 个或者 4 个字节来进行表示。如果发现错误的 UTF8 字符,则该字符会被设置为 U+FFFD 并且索引向前移动一个字节。和字符串转换一样,您同样可以使用 c := []int(s) 语法,这样切片中的每个 int 都会包含对应的 Unicode 代码,因为字符串中的每次字符都会对应一个整数。类似的,您也可以将字符串转换为元素类型为 rune 的切片:r := []rune(s)。
可以通过代码 len([]int(s)) 来获得字符串中字符的数量,但使用 utf8.RuneCountInString(s) 效率会更高一点。(参考count_characters.go)
您还可以将一个字符串追加到某一个字符数组的尾部:
var b []byte
var s string
b = append(b, s...)
7.6.2 获取字符串的某一部分
使用 substr := str[start:end] 可以从字符串 str 获取到从索引 start 开始到 end-1 位置的子字符串。同样的,str[start:] 则表示获取从 start 开始到 len(str)-1 位置的子字符串。而 str[:end] 表示获取从 0 开始到 end-1 的子字符串。
7.6.3 字符串和切片的内存结构
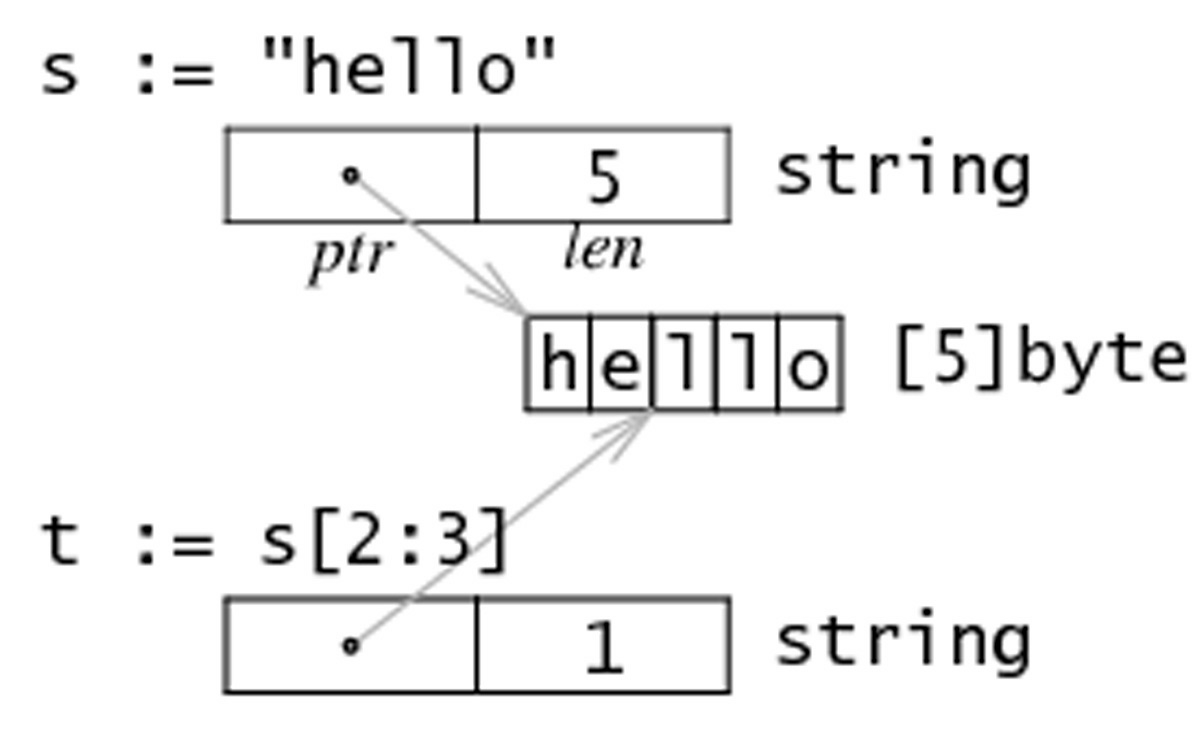
在内存中,一个字符串实际上是一个双字结构,即一个指向实际数据的指针和记录字符串长度的整数(见图 7.4)。因为指针对用户来说是完全不可见,因此我们可以依旧把字符串看做是一个值类型,也就是一个字符数组。
字符串 string s = "hello" 和子字符串 t = s[2:3] 在内存中的结构可以用下图表示:
7.6.4 修改字符串中的某个字符
Go 语言中的字符串是不可变的,也就是说 str[index] 这样的表达式是不可以被放在等号左侧的。如果尝试运行 str[i] = 'D' 会得到错误:cannot assign to str[i]。
因此,您必须先将字符串转换成字节数组,然后再通过修改数组中的元素值来达到修改字符串的目的,最后将字节数组转换回字符串格式。
例如,将字符串 "hello" 转换为 "cello":
s := "hello"
c := []byte(s)
c[0] = ’c’
s2 := string(c) // s2 == "cello"
所以,您可以通过操作切片来完成对字符串的操作。
7.6.5 字节数组对比函数
下面的 Compare 函数会返回两个字节数组字典顺序的整数对比结果,即 0 if a == b, -1 if a < b, 1 if a > b。
func Compare(a, b[]byte) int {
for i:=0; i < len(a) && i < len(b); i++ {
switch {
case a[i] > b[i]:
return 1
case a[i] < b[i]:
return -1
}
}
// 数组的长度可能不同
switch {
case len(a) < len(b):
return -1
case len(a) > len(b):
return 1
}
return 0 // 数组相等
}
7.6.6 搜索及排序切片和数组
标准库提供了 sort 包来实现常见的搜索和排序操作。您可以使用 sort 包中的函数 func Ints(a []int) 来实现对 int 类型的切片排序。例如 sort.Ints(arri),其中变量 arri 就是需要被升序排序的数组或切片。为了检查某个数组是否已经被排序,可以通过函数 IntsAreSorted(a []int) bool 来检查,如果返回 true 则表示已经被排序。
类似的,可以使用函数 func Float64s(a []float64) 来排序 float64 的元素,或使用函数 func Strings(a []string) 排序字符串元素。
想要在数组或切片中搜索一个元素,该数组或切片必须先被排序(因为标准库的搜索算法使用的是二分法)。然后,您就可以使用函数 func SearchInts(a []int, n int) int 进行搜索,并返回对应结果的索引值。
当然,还可以搜索 float64 和字符串:
func SearchFloat64s(a []float64, x float64) int
func SearchStrings(a []string, x string) int
您可以通过查看 官方文档 来获取更详细的信息。
这就是如何使用 sort 包的方法,我们会在第 11.6 节对它的细节进行深入,并实现一个属于我们自己的版本。
7.6.7 append 函数常见操作
我们在第 7.5 节提到的 append 非常有用,它能够用于各种方面的操作:
- 将切片 b 的元素追加到切片 a 之后:
a = append(a, b...) 复制切片 a 的元素到新的切片 b 上:
b = make([]T, len(a)) copy(b, a)删除位于索引 i 的元素:
a = append(a[:i], a[i+1:]...)- 切除切片 a 中从索引 i 至 j 位置的元素:
a = append(a[:i], a[j:]...) - 为切片 a 扩展 j 个元素长度:
a = append(a, make([]T, j)...) - 在索引 i 的位置插入元素 x:
a = append(a[:i], append([]T{x}, a[i:]...)...) - 在索引 i 的位置插入长度为 j 的新切片:
a = append(a[:i], append(make([]T, j), a[i:]...)...) - 在索引 i 的位置插入切片 b 的所有元素:
a = append(a[:i], append(b, a[i:]...)...) - 取出位于切片 a 最末尾的元素 x:
x, a = a[len(a)-1], a[:len(a)-1] - 将元素 x 追加到切片 a:
a = append(a, x)
因此,您可以使用切片和 append 操作来表示任意可变长度的序列。
从数学的角度来看,切片相当于向量,如果需要的话可以定义一个向量作为切片的别名来进行操作。
如果您需要更加完整的方案,可以学习一下 Eleanor McHugh 编写的几个包:slices、chain 和 lists。
7.6.8 切片和垃圾回收
切片的底层指向一个数组,该数组的实际体积可能要大于切片所定义的体积。只有在没有任何切片指向的时候,底层的数组内层才会被释放,这种特性有时会导致程序占用多余的内存。
示例 函数 FindDigits 将一个文件加载到内存,然后搜索其中所有的数字并返回一个切片。
var digitRegexp = regexp.MustCompile("[0-9]+")
func FindDigits(filename string) []byte {
b, _ := ioutil.ReadFile(filename)
return digitRegexp.Find(b)
}
这段代码可以顺利运行,但返回的 []byte 指向的底层是整个文件的数据。只要该返回的切片不被释放,垃圾回收器就不能释放整个文件所占用的内存。换句话说,一点点有用的数据却占用了整个文件的内存。
想要避免这个问题,可以通过拷贝我们需要的部分到一个新的切片中:
func FindDigits(filename string) []byte {
b, _ := ioutil.ReadFile(filename)
b = digitRegexp.Find(b)
c := make([]byte, len(b))
copy(c, b)
return c
}
练习 7.12
编写一个函数,要求其接受两个参数,原始字符串 str 和分割索引 i,然后返回两个分割后的字符串。
练习 7.13
假设有字符串 str,那么 str[len(str)/2:] + str[:len(str)/2] 的结果是什么?
练习 7.14
编写一个程序,要求能够反转字符串,即将 “Google” 转换成 “elgooG”(提示:使用 []byte 类型的切片)。
如果您使用两个切片来实现反转,请再尝试使用一个切片(提示:使用交换法)。
如果您想要反转 Unicode 编码的字符串,请使用 []int 类型的切片。
练习 7.15
编写一个程序,要求能够遍历一个数组的字符,并将当前字符和前一个字符不相同的字符拷贝至另一个数组。
练习 7.16
编写一个程序,使用冒泡排序的方法排序一个包含整数的切片(算法的定义可参考 维基百科)。
练习 7.17
在函数式编程语言中,一个 map-function 是指能够接受一个函数原型和一个列表,并使用列表中的值依次执行函数原型,公式为:map ( F(), (e1,e2, . . . ,en) ) = ( F(e1), F(e2), ... F(en) )。
编写一个函数 mapFunc 要求接受以下 2 个参数:
- 一个将整数乘以 10 的函数
- 一个整数列表
最后返回保存运行结果的整数列表。